以下のドキュメントは、Programming Historianで公開されている正規表現の演習問題を日本語に訳し、VSCode等のテキストエディタ用に処理の順序や置換パターン、説明文を一部変更したものです。
元テキストは以下から確認できます。
Doug Knox, “Understanding Regular Expressions,” Programming Historian 2 (2013), https://doi.org/10.46430/phen0033 [latest accessed: 2023-10-24].
前提となる正規表現の基本については、以下よりご確認ください。
参考:手を動かしながら覚える正規表現〈基礎入門編〉・手を動かしながら覚える正規表現〈置換処理編〉
小風綾乃(こかぜ・あやの)
東京大学史料編纂所特任研究員、お茶の水女子大学大学院博士後期課程(休学中)。
専門は18世紀フランスの科学アカデミー史。DHでは歴史補助学的なデジタル技術(Python、SQLite、TEIほか)を実践している。主な論文に「18世紀パリ王立科学アカデミー集会の出席会員分析に向けたデータ構築と可視化」、書籍に『人文学のためのテキストデータ構築入門 : TEIガイドラインに準拠した取り組みにむけて』(担当章:第2部 実践編:第2章 Transkribus実践レポート:100年分のフランス語議事録翻刻プロジェクト)がある。
その他の業績はこちらからご覧ください(researchmap)。
このレッスンの目標
この練習では、ワードプロセッサのアプリケーションでの高度な検索・置換の能力を使用して、文章の形式で表される基本的なテーブルの構造を利用します。一般的なプログラミング言語を使用せずに、計算思考の側面、特にパターンマッチングに触れることで、ワードプロセッサを使用する歴史家(および他の専門家)に直ちに役立つスキルを習得します。そして、これがより一般的なプログラミング環境での後続する学習の基盤となるでしょう。
我々は以下のような内容からスタートします:
| Arizona. — Quarter ended June 30, 1907. Estimated population, 122,931. Total number of deaths 292, including diphtheria 1, enteric fever 4, scarlet fever 11, smallpox 2, and 49 from tuberculosis. |
パターンマッチングを使用して、以下のように変換します:

正規表現とは何か、これは誰の役に立つのか?
もしかしたら、あなたはまだ「プログラミング(できる)歴史家」になりたいとは確信していないかもしれません。ただ、もっと効果的に史料と向き合いたいだけかもしれません。歴史家、図書館員、人文科学や社会科学の他の専門家は、暗黙的な構造を持つテキスト史料1をしばしば取り扱います。また、人文学では、半構造化されたノートや参考文献との面倒なテキスト作業をしなければならないことも珍しくありません。そういった場合、パターンマッチングの選択肢に関する知識が役立つことがあります。
簡単な例として、1877年という特定の年への言及をドキュメントで見つけたい場合、その日付を検索するのは簡単です。しかし、19世紀後半の年への言及を見つけたい場合、1850年、1851年、1852年などを順番に数十回も検索するのは非現実的です。正規表現を使用することで、「18[5-9][0-9]」という簡潔なパターンで1850年から1899年までの任意の年を効果的にマッチさせることができます。
この練習では、テキストエディタ(Visual Studio Code、以下VSCode)と表計算ソフト(Microsoft Excel、以下Excel)を使用します。テキストエディタは正規表現が使えるものであれば実行可能ですので、VSCodeに限定するものではありません。他の選択肢のうち有名なものでは、Atomやサクラエディタなどがあります。VSCode以外のテキストエディタを使用する場合には、以下の「VSCode」という記述を任意のテキストエディタに読み替えてください。表計算ソフトについても同様で、Googleスプレッドシート、LibreOffice Calc等、自身の使いやすいものを使用し、必要に応じて読み替えてください。
私たちはシンプルなパターンから始めますが、すぐに複雑で難解に見えるものにも取り組むことになります。ここでの目的は、もっともらしい例で有益な作業を実施する際に必要なことを共有し、単純化されたおもちゃのような例を使って基本原則に長く留まりすぎないことです。もしあなたが待ちきれないなら、すべての詳細を必ずしも追わず提供されるパターンをコピー&ペーストすることによって、適切な例を素早く一通り確認し、どんなことができるかという全体的な感覚をつかむことができます。結果が期待通りであれば、どのような詳細があなた自身の仕事に役立つかを拾い上げるために(このレッスンを)もう一度検討できるでしょう。しかし、自分自身ですべてを入力することが、それを自分のものにする最良の方法です。
このレッスンで目指すのは「実技から正規表現を身につけること」です。実際に自身の史料で実行するには正規表現の基礎が必要になりますので、このレッスンを体験して興味をもった人は以下から基礎的な学習に進むことをおすすめします。
1. テキストを入手する
Internet Archiveには、JSTORを通じてデジタル化され、”Early Journal Content”というタイトルの下で整理された、20世紀初頭のアメリカ公衆衛生報告書のパブリックドメインのコピーが数百冊収められています。これらは練習に適切な長さであり、多くの種類の歴史研究に役立つテキスト資料の広範なクラスを妥当に代表することができます。この練習では、1908年2月に公開された、アメリカの州と都市の月次死亡者数と罹患者数の統計に関する5ページの報告書を使用します。この文書はhttps://archive.org/embed/jstor-4560629から利用できます。
まずは内容に慣れるための時間を取ってください。この文書はテーブル(表)ではなく段落として整理されていますが、私たちがこれを自分たちでまとめるのに役立つ明確な潜在的な構造(パターン)があります。報告書のほぼすべての段落は、地理的情報から始まり、統計の期間を特定し、オプションで人口の見積もりを含み、その後、死亡と非致死的な病気のケースを報告しています。
ページめくりのインターフェースは、元の文書がどのように見えたかを示しています。しかし、数字をテーブルにして地理を超えた比較と計算を可能にするためには、文書をテキストと数字として、画像だけでなく表現する必要があります。Internet Archiveはダウンロードのためのいくつかの画像フォーマットを提供するだけでなく、光学文字認識(OCR)ソフトウェアによって作成されたプレーンテキストバージョンも利用できます。古いテキストのOCRはしばしば不完全ですが、それが生み出すものは画像では得られない方法で役立ちます。それはテキストとして検索、コピー、編集することができます。
(この記事に埋め込まれたビューワではなく)リンク先のページをスクロールし、ダウンロードオプションから“Full Text”ビューに切り替えます。前の報告書の最後の部分を無視して、この基点から始めます。VSCode(任意のテキストエディタ)を開き、ファイルを新規作成(左上のメニューから”File”→”New text file”)したあと、“STATISTICAL REPORTS…”から終わりまでのテキストをそのファイル(.txt)にコピー&ペーストしてください。大切な資料を取り扱う際には、何かがうまくいかなかった場合に元に戻すために、作業用のコピーとは別の場所にコピーを保存することを忘れないでください。
ファイルの保存方法(クリックすると開きます)
- 左上のメニューから”File(ファイル)”→”Same As(名前を付けて保存)”
- 任意のファイル名を入力し、最後に.txtという拡張子をつける(例:”statistical_report.txt”)
- 下のファイルフォーマット選択部分を「すべてのファイル」または「プレーンテキスト」に変更する(デフォルトではTeXになっているかも)
- 「保存」ボタンをクリックする
2. 紙面の汚れに起因した不要な文字を消す(通常の検索と置換)
2-1. ダブルクォーテーションの削除
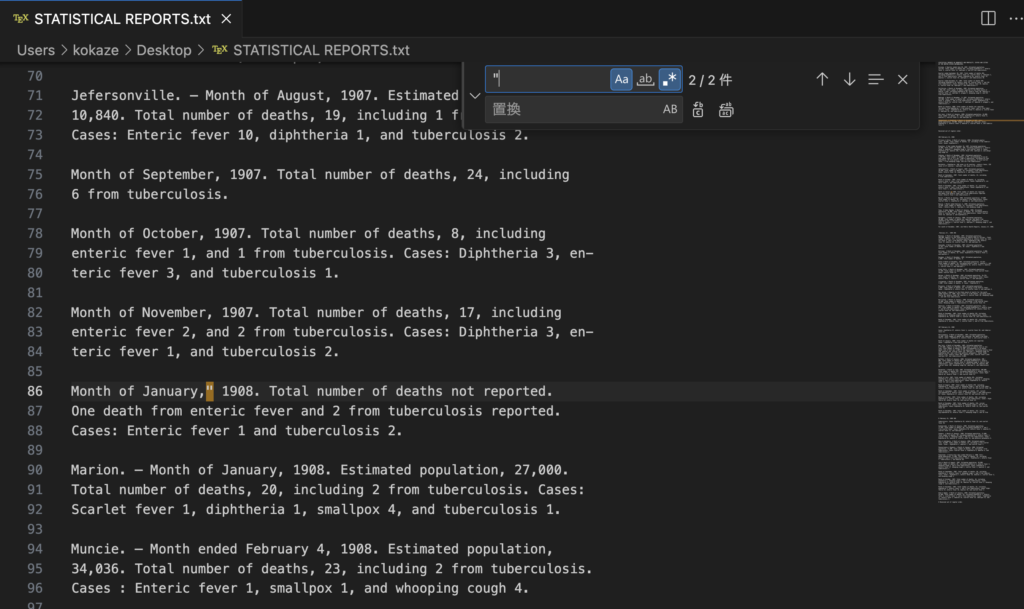
光学文字認識(OCR)のエラーがいくつか確認できます。Internet Archiveの自動翻刻ソフトウェアが誤認識した部分ですが、大部分は良好な翻刻のように見えます。このファイルではOCRが誤って2か所にダブルクォーテーションマークを挿入しているのが確認できます。両方のケースで、月の後に続くカンマと4桁の年の間にそれらを置いています。
例
| December,” 1907. |
私たちはダブルクォーテーションマーク(”)を検索(ヘッダーメニューから選ぶ場合は編集 → 検索;ショートカットはWindows: Ctrl+F, Mac: command+F)から探し、このファイル内に2つだけクォーテーションマークのインスタンス(例)を確認することができます。この場合、単純にこれらを削除することができます。手作業で行うのではなく、練習のためにVSCodeの検索と置換機能(Windows: Ctrl+H, Mac: command+option+F)を使用してみてください。
| マッチパターン | 置換文字列 | 一致パターン | 補足 |
| “ | 2件 | 置換後に何も入力しなければ、置換前に指定した文字列(パターン)が削除される | |
| ダブルクォーテーション | (何もなし) |
3. 行の構造を探す
まだ始まったばかりですが、どれくらいの進捗があるかを評価するために、VSCodeで全文を選択(Ctrl+A)し、それをExcelに貼り付けます(ファイル->新規->スプレッドシート)。テキストの各行がスプレッドシートの一つのセルとなる行になります。私たちが望むのは、スプレッドシートの各行が一貫した形で一つの種類のレコードを表すことです。これを出発点として手作業でこれを表にまとめるのは非常に手間がかかります。以下で説明するのは、VSCodeで正規表現を使用してすべての作業を行う方法ですが、Excelはバックグラウンドで開いたままにしておいてください。進行状況を測定するために、将来的にそれに貼り付けることができます。
VSCodeに戻ると、必要のない行の区切りを取り除きたくなりますが、まず最初に行末のハイフネーションを整理する必要があります。このとき、行間のマッチングに関して正規表現が行内のパターンのマッチングの特徴とは異なることに注意して正規表現を使用し始めます。
3-1. 行末を#でマークする
テキストエディタの正規表現は行の区切りを越えて拡張されるテキストのパターンには容易にマッチしないので、間接的な戦略を採用します。まず、テキスト内でほかに現れないプレースホルダー文字—ここでは「#」を使ってみましょう — で行の区切りを置き換えます。
「検索&置換」ボックス(Windows: Ctrl+F, Mac: command+F)で「詳細オプション」(Macでは「その他のオプション」)を表示し、「正規表現」のチェックボックスが選択されていることを確認します。これにより、一般的なパターンをマッチさせるために特別なシンボルを使用することができます。
検索と置換を使用して、$を#に置換しましょう。
| マッチパターン | 置換文字列 | 一致パターン |
| $ | # | 290 |
| ドル | シャープ |
ドル記号($)は、伝統的に各行の終わりをアンカーとして大きなパターンにマッチさせるための特殊な記号です。VSCodeではこの機能を大きなパターンで使用することができますが、行の区切りをまたいでテキストをマッチさせることはできません。しかし、VSCodeでは他のパターンなしで$文字をそのまま使用して、他の文字とは無関係に行の区切りをマッチさせて置き換えることができます。
検索と置換の操作を行うには、まず「検索」をクリックして、ハイライトされた選択が期待どおりであることを確認したら「置換」をクリックします。これを数回繰り返した後、「すべて置換」をクリックして、残りのすべてを一度に置換します。間違いを犯したり、確信が持てない場合は、メニューバーの「編集」→「元に戻す」や、キーボードのショートカットCtrl+Z(Macの場合はcommand+Z)で直近の操作を元に戻すことができます。
この文書で行の終端を置換すると、290個の置換が行われます。 (コピーした行の数によっては、あなたの数字がわずかに異なる可能性があります。) この置換のシーケンスにより、テキストは一時的に読みづらくなりますが、行の区切りをまたいでパターンをマッチさせることはできないが、#文字をまたいでマッチさせることはできるので、この操作は必要です。
3-2. ハイフンで改行された単語をひとつにまとめる
次に、ハイフンで綴られた単語を詰めましょう。実際、これは一般化されたパターンマッチングに頼ることなく、文字通りの置換で実現することができます。
再び検索と置換を使用して、
-[ ]#\n(ハイフン-スペース-ハッシュ-バックスラッシュ-エヌ)を何もない状態に置き換えます。
| マッチパターン | 置換文字列 | 一致パターン |
| -[ ]#\n | 27 | |
| ハイフン-スペース-ハッシュ-バックスラッシュ-エヌ | (何も入力しない) |
「[ ]」はハイフンの後にスペースを入れていることをわかりやすくするために使います。
「\n」は改行を示すパターンです。
これにより「tuber- #culosis」といったパターンが「tuberculosis」として1行にまとまり、この場合、合計27個の置換が行われます。
3-3. 文字のない空白行についた#を削除する
次に、\n#を\nで置き換えます(70件の一致)。
| マッチパターン | 置換文字列 | 一致パターン |
| \n# | \n | 75 |
| バックスラッシュ-エヌ-シャープ | バックスラッシュ-エヌ |
これにより75個の置換が行われます。 このステップでは、元々は段落の区切りであったものが、2行の区切りとして##で表されていたものを、実際の1行の区切りに戻します。 これらは、スプレッドシートの文脈において新しい行をマークする機能として機能します。
3-4. 行末の#を削除し、行の区切り作業を完了する
行の区切り作業を終了するには、すべての#を消します。
用いる資料によっては、#の前に半角スペースが入っていないかもしれません。
#の前に半角スペースがない場合は、置換文字列に半角スペースを入れるように気をつけてください。
| マッチパターン | 置換文字列 | 一致パターン |
| #\n | 187 | |
| シャープ-バックスラッシュ-エヌ | (何も入力しない) |
これにより、元のテキストの段落の区切りではない187の行の区切りが取り除かれます。
最初は何が起こったのかはっきりとわからないかもしれませんが、これにより各段落が単一の段落または行となりました。
より有用な構造になっていることを確認する最後の方法として、再びVSCodeから全テキストをコピーして、何も入力されていないスプレッドシートに貼り付けてみましょう。 これにより、各健康記録がスプレッドシートの別々の行として現れることが確認されます(ページの見出しと脚注も混在していますが、これらは間もなくクリーンアップします)。

4. 列の構造を見つける
スプレッドシートは情報を2つの次元、行と列で整理します。VSCodeの行がExcelの行に対応することはわかりましたが、どうやって列を作成しましょうか?
スプレッドシートソフトウェアでは、列間の区切りを示すいくつかの規約を使用してプレーンテキストファイルを読み書きすることができます。一般的な形式の1つは、列を区切るためにカンマを使用します。このようなファイルは、「カンマ区切りの値」を意味する“.csv”の拡張子で保存されることがよくあります。もう1つの一般的な形式は、列を区切るためにタブ文字(特殊なスペースの一種)を使用し、“.tsv”の拡張子で保存することです。テキストにカンマが含まれているので、混乱を避けるために、ここでは列の区切りとしてタブ文字「\t」を使用します。この演習では、VSCodeからExcelに直接コピー&ペーストすると仮定して、中間のプレーンテキストファイルを保存することはありません2。
ただし、これ以降の作業でタブ処理がうまくExcelに反映されない場合は、tsv形式で保存してExcelにインポートするようにしてください。
tsv形式で保存する方法(クリックすると開きます)
- 「名前を付けて保存する」画面を開き、下部のフォーマットでtsvを選択
- tsvの選択肢が出てこない場合は、フォーマットを「すべてのファイル」にした上でファイル名の最後についている.txtを.tsvに変更する
- 「保存」する
4-1. 死者数以降をタブで区切る
VSCodeに戻り、場所と時間の情報を報告された数字から分けた列を作成しましょう。ほとんどすべてのレポートには次の言葉が含まれています。
Total number of deaths
これを検索し、文字列の先頭に“\t”を持つまったく同じフレーズに置き換えて、タブ文字を表すようにします。
| マッチパターン | 置換文字列 | 一致パターン |
| Total number of deaths | \tTotal number of deaths | 53 |
| 先頭にバックスラッシュ-ティーを追加 |
(別解)
| マッチパターン | 置換文字列 | 一致パターン |
| (Total number of deaths) | \t$1 | 53 |
| 半角括弧()で文字列を囲む | バックスラッシュ-ティー-ドル-数字の1 |
この置き換えを行った後、テキスト全体を選択してコピーし、空のスプレッドシートにペーストします。
tsv形式で保存する方法(クリックすると開きます)
- 「名前を付けて保存する」画面を開き、下部のフォーマットでtsvを選択
- tsvの選択肢が出てこない場合は、フォーマットを「すべてのファイル」にした上でファイル名の最後についている.txtを.tsvに変更する
- 「保存」する
【tsv形式で保存した人向け】tsv形式のファイルをExcelで開く方法(クリックすると開きます)
- Excelメニューの「ファイル」から「インポート」を選択
- インポートするファイルの種類で「csvファイル」にチェックを入れ、「インポート」をクリック
- 取り込むファイルを選び、「データ取り出し」をクリック
- テキストファイルウィザードで「区切り記号付き」にチェックを入れ、元のファイルでプルダウンから「Unicode (UTF-8)」を選んだら「次へ」を押す
- 区切り文字として「タブ」にだけチェックを入れ、「完了」をクリック
- データを返す先(=出力する先)として白紙になっているシートを選び(とくにデータが書かれていなければ「既存のシート」で問題ない)、「インポート」をクリックする
何も変わっていないように見えますか?目の前のExcelは各段落の全文がタブごとに1つのセルに入っているはずです。
Total number of以下がB列に入っていれば処理成功です。
A列にはまだ地理と時間範囲がありますが、「死亡総数」とその後のテキストが明確に別の列に整列していることがわかります。
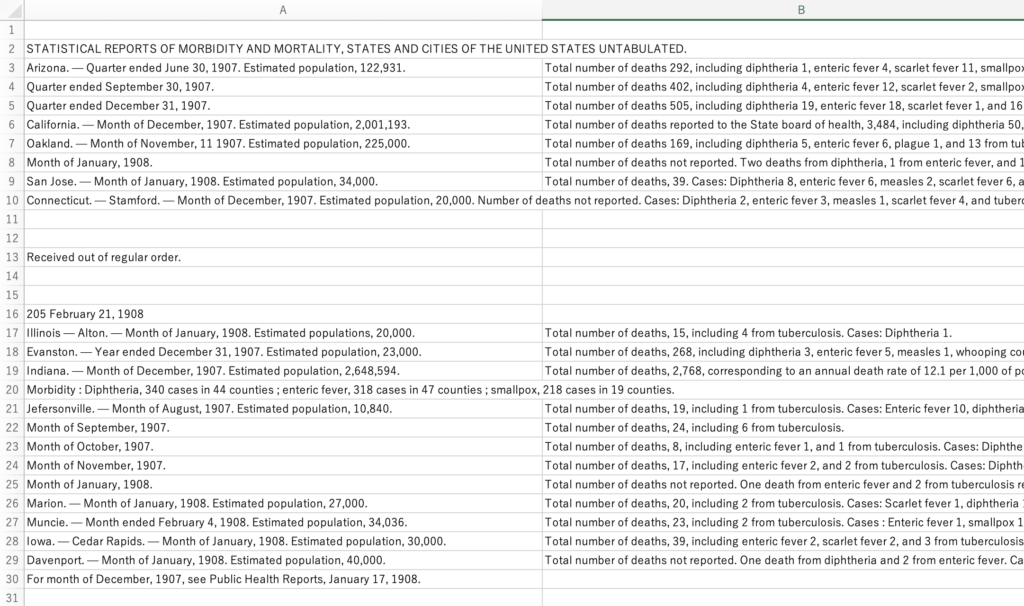
C列やそれより右に移動したインスタンスはありますか?その場合、多くのタブ(\t)を誤って入れてしまった可能性があります。現在の構造では、2つのタブ文字が連続して表示されることは期待していません。C列以降にTotal number以降が表示された場合はVSCodeに戻り、以下のものを検索して問題をチェックおよび修正します。
| マッチパターン | 置換文字列 | 補足 |
| \t\t | \t | C列以降に表示された場合のみ実施 |
| バックスラッシュ-ティー-バックスラッシュ-ティー | バックスラッシュ-ティー |
これをタブの連続が見つからなくなるまで繰り返します。
置換パターンを複数回適用することにより追加の変更が導入されることがあり、それが意図するものであるかどうかが問題となります。また、複数回の適用が最初にした適用を超えて何の影響も及ぼさないこともあります。正規表現で作業する間はこの違いを心に留めておく価値があります。
5. 正規表現の一般的な考え方
ファイルでの実際の作業をさらに進める前に、正規表現について簡単に紹介するのが良い頃合いです。正規表現(「Regular Expressions」短くして「regexes」とも呼ばれます)は、事物の並びに適用できるパターンを定義する方法です。コンピュータサイエンスや形式言語理論の起源に由来するため、このような名前がついています。そして、ほとんどの一般的なプログラム言語に組み込まれています。
正規表現は、高度なワードプロセッサでも一部の形で利用可能であり、文字ごとに正確な並びを一致させるよりも強力な検索と置換の手段を提供します。正規表現の構文や実装には違いがあり、ワード処理プログラムで利用可能なものは、プログラム言語の文脈で見られるものと同じくらい広範囲で頑健、または一般的な慣習に準拠しているわけではありませんが、基本的な共通の原則があります。VSCodeは、大部分で他の文脈で見られる表記法に従っています。独自のワードプロセッサを使用している場合、表記が異なる場合でも同様の機能が見られる可能性が高いです。
| マッチパターン | 説明 |
|---|---|
| A b 1 | 文字・数字等を指定したもの |
| [Ab1] | A, b, 1のいずれか |
| [a-z] | aからzのいずれか(アルファベット小文字1字) |
| [0-9] | 0から9のいずれか(数字1文字) |
| . | 任意の1文字 |
| * | 0回以上の繰り返し |
| + | 1回以上の繰り返し |
| {10} | 繰り返し回数指定(10回)。3回なら{3} |
| ( ) | グループ化 |
| $1 | グループ化したものの参照(1番目)。2番目なら$2 |
| \t | タブ |
| ^ | 行頭 |
| $ | 行末 |
| \n | 改行 |
この表に出てくるマッチパターンは本当によく使うものばかりですので、ぜひ覚えておいてください。
6. 正規表現の適用
6-1. 日付とページ番号を含むヘッダーとフッターを削除する
これらの中からいくつかを使用して、日付とページ番号を含むページヘッダーを削除しましょう。VSCodeのウィンドウに戻ってください。
| マッチパターン | 置換文字列 | 一致パターン |
| ^.*February 21.*1908.*$ | ||
| キャレット-ピリオド-アスタリスク-February-半角スペース-21-ピリオド-アスタリスク-1908-ピリオド-アスタリスク-ドル | (何も入力しない) | 4 |
| 行頭-任意の文字-0回以上の繰り返し-February-半角スペース-21-任意の文字-0回以上の繰り返し-1908-任意の文字-0回以上の繰り返し-行末 |
ここで、^(キャレット)は行の始まりを、.(ピリオド)は任意の文字を、.*(ピリオドアスタリスク)は0回以上の任意の文字の繰り返しを、\n(バックスラッシュ-エヌ)は改行を表します。日付を具体的に指定することで、その文字列が文字ごとに表示される行だけを一致させ、行の前後に何があるかに関係なく、その文字列が含まれるすべての行とマッチさせます。
次に、フッターを削除します。フッターは
| マッチパターン | 置換文字列 | 一致パターン |
| ^.*Received.*$ | 2 | |
| キャレット-ピリオド-Received-ピリオド-ドル | (何も入力しない) | |
| 行頭-任意の1文字を0回以上繰り返し-Received-任意の1文字を0回以上繰り返し-行末 |
これらの置換処理を行うと、いくつかの空白行が残ります。
6-2. 空白行を削除する
空白行を削除するには、「^\n」を空欄で置き換えます。
| マッチパターン | 置換文字列 | 一致パターン |
| ^\n | 15 | |
| キャレット-バックスラッシュ-エヌ | (何も入力しない) |
(他の正規表現の環境では、行の終端を扱うための他の技術が必要になることがあります。VSCodeが提供するものよりも便利なものもあるかもしれませんが、今回の目的のためにはこれで十分です。)
6-3. 正規表現の限界(と対策)を認識する
一部の記録には州がリストされているものもあり、都市が暗黙のうちに州としてリストされているものもあります。テキストには、カリフォルニアとオークランドの記録を区別するための信頼性のある方法を提供する十分な構造がありません。したがって、自動的にカリフォルニアを州の列に、オークランドを都市の列に配置することはできません。私たちは最終的に手作業で編集を行う必要があり、自分たちの知識に基づいて行います。しかし、時間の範囲に関する言及には一貫性があります。これらの参照を使用して、類似のセグメントを行を超えて整列させるのに役立つ構造を開発することができます。
便宜上、テキストに既存のものと混同されないマーカーをいくつか追加しましょう。これらのマーカーは既存のテキストと容易に区別でき、後で必要なくなったら簡単に削除できます。次章では時間の範囲の参照に一致させて、それらの始まりに<t>を、終わりに</t>を置きます。ここで、”t”は”time”の略語です。もっと詳細なマーカーを追加することもできますが、今回の演習では<t>のようなマーカーを使用します。HTMLやXMLを見たことがあるなら、これらは要素をマークするタグによく似ていることがわかるでしょう。しかし、これによって正しいHTMLや整形の良いXMLを作成しているわけではありません。そして、これらのマーカーはすぐに削除しますが、似たようなものです。
義務的な警告:正規表現は強力ですが、限界があります。また、誰かが気にする材料を変更するために使用される場合、間違いによって情報が誤って削除されたり混乱する可能性があり危険です。XMLの愛好家は熱心に、正規表現はXMLの一般的な解析には適していないと言うでしょう。特定の種類のパターンを処理するのに正規表現が有用であることがわかると、コンピュータが助けてくれるはずのパターンを見るたびに、正規表現だけが必要であると考える誘惑があります。多くの場合、それが真実でないことがわかります。正規表現は、XMLが良く説明するような階層的にネストされたパターンを扱うのに十分ではありません。
しかし、いまのところは大丈夫です。このチュートリアルの文脈では、XMLについて特に何も知らない、または形式言語文法を気にしていないことを前提にしています。私たちが行いたいのは、比較的簡単な暗黙の構造を少し明示的にするための手がかりとしてテキストにいくつかの便利なマーカーを追加することです。そして、作業が終わる前にこれらのマーカーを取り除きます。このようなマーカーが有用である理由があります。この演習でパターンを使用してできることに興味を持っているなら、HTMLやXMLについてもっと学びたいかもしれません。そして、そのより明確な構造が可能にする適切な方法で何ができるかを学びたいかもしれません。
7. セグメントの定義
次のいくつかのパターンは急速に複雑になります。しかし、シンボルがパターンをどのように定義するかの参照を参照するために速度を落とすならば、これらのパターンが意味を持ち始めるはずです。
7-1. 地名とそれ以外のデータをタブで分ける
私たちのテキストにおける地理的な言及の後には、「—」(エムダッシュ。文字「m」の幅ほどのダッシュ;「-」エンダッシュよりも広い)が続きます。これらをタブ文字に置き換えることで、スプレッドシートの別々の列に州や都市を配置するのに実質的に役立ちます。
| マッチパターン | 置換文字列 | 一致パターン |
| [ ]?—[ ]? | \t | 42 |
| 角括弧-半角スペース-角括弧-クエスチョン-エムダッシュ-角括弧-半角スペース-角括弧-クエスチョン | バックスラッシュ-ティー | |
| スペースがあるかも([ ]?)-エムダッシュ-スペースがあるかも([ ]?) | タブを入れる |
角括弧は必ずしも必要ありませんが、私たちが空白スペースをマッチさせている事実を明確にするのに役立ちます 。 クエスチョンマークのおかげでオプションとしてマッチさせます。これは、エムダッシュの前後のどちらか、または両方の側にスペースがあるかどうかにかかわらず、私たちのパターンがエムダッシュを受け入れることを意味します。)
7-2. 時間に関する記述を<t>〜</t>で囲む
次に、時間への明示的な参照を探し、それらの前後に“”および“”マーカーで囲みます。これらのマーカーを持つと、さらにパターンを構築できる足場を提供してくれます。次のパターンでは、置き換えを一度だけ適用することを確認したいです。そうしないと、時間の参照が繰り返し囲まれるかもしれません。ラッピングパターンごとに一度だけ「すべて置き換える」を使用するのが最も効率的です。
正規表現では一括置換できるのが利点なので「すべて置換」をよく使うことになりますが、「すべて置換」ボタンをクリックする前に必ずそのパターンに例外が含まれていないかを確認しましょう。
確認せずに「すべて置換」を繰り返し、後から間違いに気づいても修正できないかもしれません。
時間に言及しているのは、Month of …というパターンと、… ended …というパターンの2つなので、それぞれパターンマッチングさせていきましょう。
ここから先は正規表現「.*」に加えて大文字と小文字を区別する「Aa」のオプションもオンにしましょう。
| マッチパターン | 置換文字列 | 一致パターン |
| (Month of [A-Z][a-z, 0-9]+ 19[0-9][0-9].) | <t>$1</t> | 48 |
| 丸括弧-Month-半角スペース-of-半角スペース-[A-Z]-[a-z, 0-9]-プラス-半角スペース-19-[0-9]-[0-9]-ピリオド-丸括弧 | 小なり-ティー-大なり-ドル-1-小なり-スラッシュ-ティー-大なり | |
| 置換文字列で参照するための丸括弧-Month of -任意の大文字アルファベット-任意の小文字アルファベット/カンマ/半角スペース/任意の数字のいずれかを1回以上の繰り返し-半角スペース-19-任意の数字-任意の数字-任意の1文字 | マッチパターンの丸括弧で囲った部分を参照し、それらを<t>(tの開始タグ)と</t>(tの終了タグ)で囲む |
ここでは、検索パターン内のマッチ全体を単一のグループとして定義するために丸括弧を使用しており、置き換えパターンでは$1を使用してそのマッチを単純に繰り返し、それの前後にいくつかの追加文字を加えています。
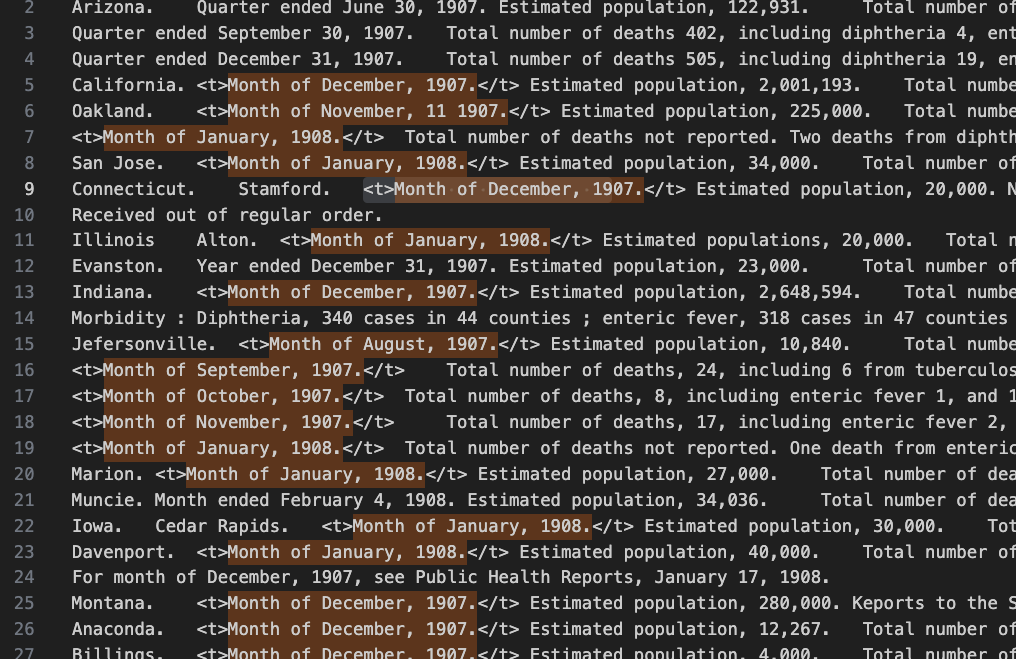
ここで、23行目は手動でタグをつけてしまいましょう。
| マッチパターン | 置換文字列 | 一致パターン |
| (For month of December, 1907, see Public Health Reports, January 17, 1908.) | <t>$1</t> | 1 |
| 丸括弧-For month以下の文字列-丸括弧 | 小なり-ティー-大なり-ドル-1-小なり-スラッシュ-ティー-大なり |
一括ではマッチできなかった例外をその都度探し修正していくことが綺麗なデータを作るコツです。
月の情報と同様のアプローチで四半期報告も一致させる必要があります:YearやQuarter、Monthなどの単語とともに時間の参照が考慮されているようです。
| マッチパターン | 置換文字列 | 一致パターン |
| ([-A-Za-z ]+ ended [A-Z][a-z, 0-9]+ 19[0-9][0-9].) | <t>$1</t> | 7 |
| 丸括弧-角括弧-ハイフン-A-ハイフン-Z-a-ハイフン-z-半角スペース-角括弧-プラス-半角スペース-ended-半角スペース-角括弧-A-ハイフン-Z-角括弧-角括弧-a-ハイフン-z-カンマ-半角スペース-0-ハイフン-9-角括弧-プラス-半角スペース-19-角括弧-0-ハイフン-9-角括弧-角括弧-0-ハイフン-9-角括弧-ピリオド-丸括弧 | 小なり-ティー-大なり-ドル-1-小なり-スラッシュ-ティー-大なり | |
| ハイフン/任意の大文字アルファベット/任意の小文字アルファベット/半角スペースのいずれかを1回以上繰り返し-ended-半角スペース-任意の大文字アルファベット-任意の小文字アルファベット/カンマ/スペース/任意の数字を1回以上繰り返し-半角スペース-19-任意の数字-任意の数字-任意の1文字-これらの文字列をすべて後ほど参照する | マッチパターンの丸括弧で囲った部分を参照し、それらを<t>(tの開始タグ)と</t>(tの終了タグ)で囲む |
7-3. 人口に関する記述を<p>〜</p>で囲む
ここでの他の情報の種類にこの戦略を拡張し、<p>(population)を人口の見積もりのために、<N>(number)を死亡の総数のために、そして<c>を死亡者数から罹患者数を分離する”Cases”という単語のために使用しましょう。(HTMLやXMLに精通している場合、<p>を段落マーカーとして認識するかもしれませんが、ここではその意味で使用していません。)
以下はその種の情報のそれぞれをマッチさせるためのいくつかのパターンで、すべて先ほど使用したのと同じ戦略を使用しています:
| マッチパターン | 置換文字列 | 一致パターン |
| (Estimated population[s]?, [0-9,]+.) | <p>$1</p> | 35 |
| 丸括弧-Estimated-半角スペース-populations-角括弧-s-角括弧-クエスチョン-カンマ-半角スペース-角括弧-0-ハイフン-9-カンマ-角括弧-プラス-ピリオド-丸括弧 | 小なり-ピー-大なり-ドル-1-小なり-スラッシュ-ピー-大なり | |
| Estimated population-sがあってもなくてもマッチ-カンマ-半角スペース-任意の数字/カンマのいずれかを1回以上繰り返し-任意の1文字-これらの文字列をすべて後ほど参照する | マッチパターンの丸括弧で囲った部分を参照し、それらを<p>(pの開始タグ)と</p>(pの終了タグ)で囲む |
7-4. 死亡総数を<N>〜</N>で囲み、死亡総数以降の記述を右列に移動する
次に、死亡総数を<N>で囲み、例外も処理してから、右列にタブを分けていきましょう。
| マッチパターン | 置換文字列 | 一致パターン |
| (Total number of deaths[A-Za-z ,]* [0-9,]+[,.]) | <N>$1</N> | 48 |
| 丸括弧-Total number of deaths-角括弧-A-ハイフン-Za-ハイフン-z-半角スペース-カンマ-角括弧-アスタリスク-半角スペース-0-ハイフン-9-カンマ-角括弧-プラス-角括弧-カンマ-ピリオド-角括弧-丸括弧 | 小なり-大文字エヌ-大なり-ドル-1-小なり-スラッシュ-大文字エヌ-大なり | |
| Total number of deaths-任意の大文字・小文字アルファベット/半角スペース/カンマのいずれかを0回以上繰り返し-半角スペース-任意の数字/カンマのいずれかを1回以上繰り返し-カンマ/ピリオドのどちらか-これらの文字列をすべて置換後に参照する | マッチパターンの丸括弧で囲った部分を参照し、それらを<N>(Nの開始タグ)と</N>(Nの終了タグ)で囲む |
テキストを眺めてみると、死亡総数にはたくさんの例外的表現が見つかります。以下、順に処理していきます。
| マッチパターン | 置換文字列 | 一致パターン |
| (a total of [0-9,]+ deaths,) | <N>$1</N> | 1 |
| 丸括弧-a total of-半角スペース-角括弧-0-ハイフン-9-カンマ-角括弧-プラス-半角スペース-deaths-カンマ-これらの文字列をすべて置換後に参照する | 小なり-大文字エヌ-大なり-ドル-1-小なり-スラッシュ-大文字エヌ-大なり |
| マッチパターン | 置換文字列 | 一致パターン |
| (Total number of deaths not reported\.) | <N>$1</N> | 5 |
| 丸括弧-Total number of deaths not reported-バックスラッシュ(エスケープ)-ピリオド-丸括弧 | 小なり-大文字エヌ-大なり-ドル-1-小なり-スラッシュ-大文字エヌ-大なり | |
| Total number of deaths not reported-ピリオドを文字として入れたいのでエスケープする-これらの文字列をすべて置換後に参照する |
| マッチパターン | 置換文字列 | 一致パターン |
| (Number of deaths not reported\.) | <N>$1</N> | 1 |
| 丸括弧-Number of deaths not reported-バックスラッシュ(エスケープ)-ピリオド-丸括弧 | 小なり-大文字エヌ-大なり-ドル-1-小なり-スラッシュ-大文字エヌ-大なり |
これで例外の処理が終わったので、死亡総数以降の記述を右列に動かすタブ区切りの作業をしましょう。
| マッチパターン | 置換文字列 | 一致パターン |
| ^(.*?)<N> | $1\t<N> | 55 |
| キャレット-丸括弧-ピリオド-アスタリスク-クエスチョン-丸括弧-小なり-大文字エヌ-大なり | ドル-1-バックスラッシュ-ティー-小なり-大文字エヌ-大なり | |
| 文頭-<N>より前にあるすべての文字列(?は最短一致の意味で使用)-<N>より前にあるすべての文字列を置換後に参照する | マッチパターンの丸括弧で囲った部分を参照-タブ区切り-<N> |
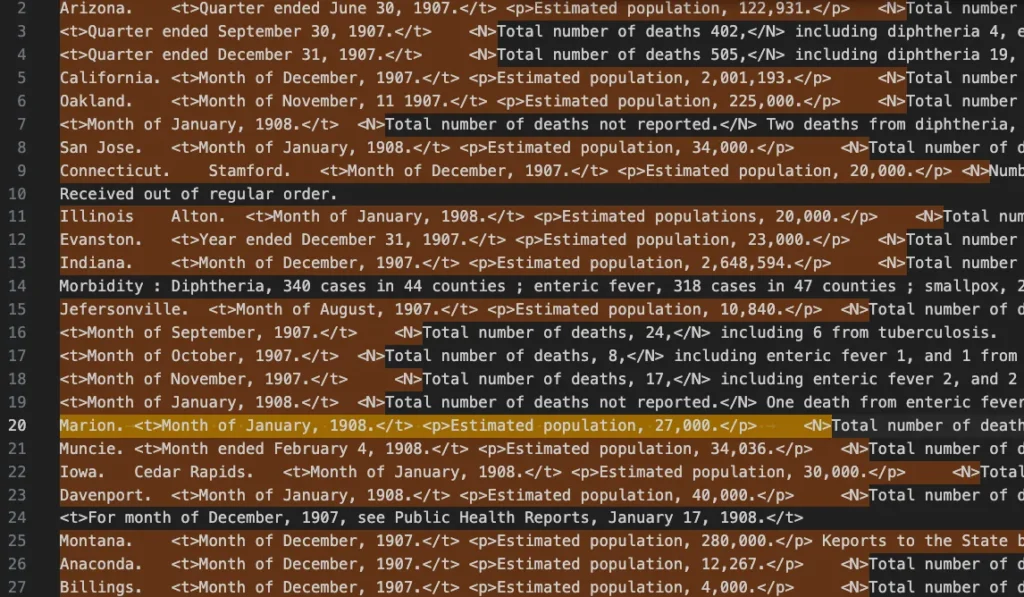
例外を探すコツは、次に進む前にパターンを精査することです。死亡総数を例に説明すると、このタブ処理のマッチパターンを入力したとき、マッチしていない死亡総数の行がないかをチェックし、該当するものがあれば先に処理することでミスを防げます。
7-5. 罹患者数を<c>〜</c>で囲む
死亡者数から罹患者数を分離するCasesという目印を<c>タグで囲みます。
| マッチパターン | 置換文字列 | 一致パターン |
| (Cases[ ]?:) | <c>$1</c> | 49 |
| 丸括弧-Cases-半角スペース-クエスチョン-コロン-丸括弧 | 小なり-シー-大なり-ドル-1-小なり-スラッシュ-シー-大なり | |
| Casesの後ろに半角スペースがあるかどうかは問わない([ ]?)-全体を置換後に参照 |
罹患者数は症状ごとに書いてあり複雑なので、Cases:という文字列だけをタグで囲んでいます。
7-6. A列に入るべき要素以外の改行を整える
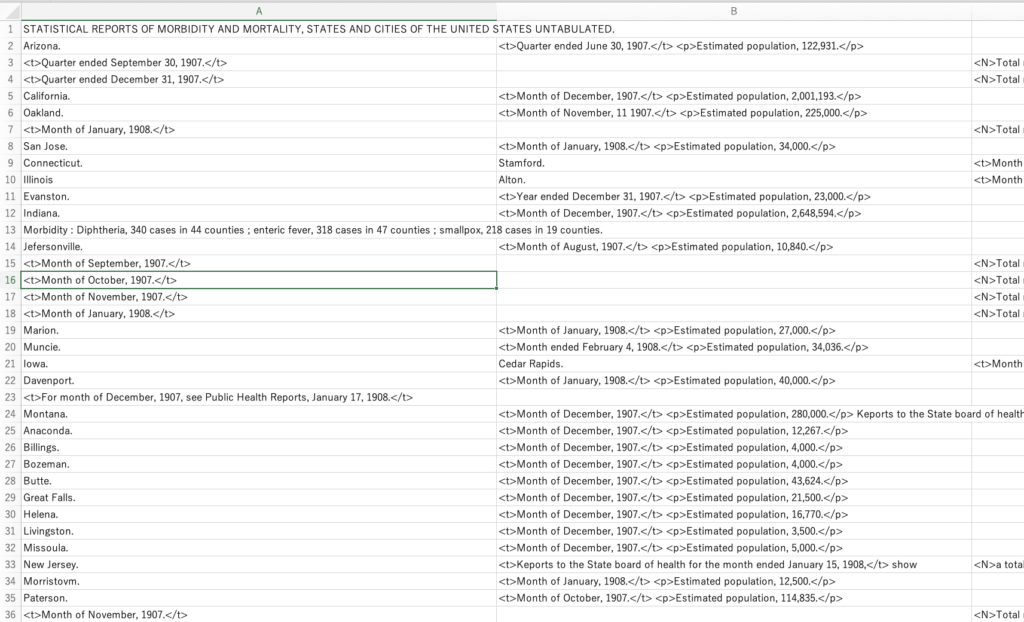
これまでの成果をExcel画面で確認してみましょう。テキストを全選択して貼り付けるか、tsv形式で保存したファイルをインポートします。
【参考・再掲】tsv形式で保存する方法(クリックすると開きます)
- 「名前を付けて保存する」画面を開き、下部のフォーマットでtsvを選択
- tsvの選択肢が出てこない場合は、フォーマットを「すべてのファイル」にした上でファイル名の最後についている.txtを.tsvに変更する
- 「保存」する
【参考・再掲】tsv形式のファイルをExcelで開く方法(クリックすると開きます)
- Excelメニューの「ファイル」から「インポート」を選択
- インポートするファイルの種類で「csvファイル」にチェックを入れ、「インポート」をクリック
- 取り込むファイルを選び、「データ取り出し」をクリック
- テキストファイルウィザードで「区切り記号付き」にチェックを入れ、元のファイルでプルダウンから「Unicode (UTF-8)」を選んだら「次へ」を押す
- 区切り文字として「タブ」にだけチェックを入れ、「完了」をクリック
- データを返す先(=出力する先)として白紙になっているシートを選び(とくにデータが書かれていなければ「既存のシート」で問題ない)、「インポート」をクリックする
A列に入っているのは基本的に地名と時間への言及です。そうではない要素は本来前列に入っているべきものですので、手動で改行を削除していきましょう。
このファイルでいうと、以下の部分です。削除はExcelではなくVSCode上で行なってください。
50行目:tuberculosis. 〜
38行目:<c>Cases:</c> 〜
13行目:Morbidity〜
文章の後ろ側から削除していけば行数が変わらないため、該当箇所を探しやすいです。
なお、これらを正規表現で一括処理するには以下のように入力します(応用)。
| マッチパターン | 置換文字列 | 一致パターン |
| \n(tuberculosis\.|<c>Cases:</c>|Morbidity) | $1 | 3 |
| バックスラッシュ-丸括弧-tuberculosis-バックスラッシュ-ピリオド-パイプ-Cases-コロン-パイプ-Morbidity-丸括弧 | ドル-1 | |
| 改行-tuberculosis./<c>Cases:</c>/Morbidityのいずれかの記述を置換後に参照する | マッチパターンの丸括弧で囲った部分を参照 |
ここで、1つ例外に気がつくかもしれません。12行目に移したMorbidityは、前後の構造から判断してCasesに該当する用語であると判断できます。そのためここでは、Casesと同じくMorbidityを<c>タグで囲んでおきましょう。
| マッチパターン | 置換文字列 | 一致パターン |
| (Morbidity 🙂 | <c>$1</c> | 1 |
| 丸括弧-Morbidity :-丸括弧 | 小なり-シー-大なり-ドル-1-小なり-スラッシュ-シー-大なり |
7-7. 数字を適切に扱うための準備
この先では数字を扱うので、そのための準備をしておきましょう。処理したい内容は以下の2つです。
- 桁区切りのカンマと項目区切りのカンマを区別する
- 英数字を算用数字に置き換える
まず桁区切りのカンマと項目区切りのカンマを区別するために、数値の後のカンマ(=項目区切りのカンマ)を削除しておきましょう。
| マッチパターン | 置換文字列 | 一致パターン |
| ([0-9]),[ ] | $1 | 249 |
| 丸括弧-角括弧-0-ハイフン-9-角括弧-丸括弧-カンマ-角括弧-半角スペース-角括弧 | ドル-1-半角スペース |
疾患名が羅列されている部分からほとんどのカンマが消えたことがわかると思います。疾患名のリストに残っているのは桁区切りのカンマです。
次に、英数字を算用数字に置き換えていきましょう。数字は検索欄に入力して確かめると良いですが、今回の場合はoneとtwoの例があります。
| マッチパターン | 置換文字列 | 一致パターン |
| One | 1 | 3 |
| マッチパターン | 置換文字列 | 一致パターン |
| Two | 2 | 1 |
もし英数字が大文字・小文字混在だった場合には、「大文字・小文字を区別する」オプション(「Aa」)を外すとどの書き方でもマッチします。
7-8. 疾患名と罹患者・死亡者数を1項目ずつタブに分ける
次の部分は少し難しくなります。疾患(<d>を使用しましょう)とカウント(<n>を使用します)のセグメントを取得していきましょう。この散文は非常に公式的であるため、各疾患の名前を明示的に一つずつマッチさせることなくかなりの作業を進めることができます。まず、”including”の後の疾患-カウントのペアをマッチさせます。
疾患名を<d>タグで、死亡者数を<n>タグで囲みましょう。疾患名→死亡者数のパターンと、死亡者数→疾患名のパターンがあります。
7-8-1. including 疾患名→罹患者・死亡者数
| 置換前 | including diphtheria 4 enteric fever 12 |
| 置換後 | <d>diphtheria</d> <n>4</n> enteric fever 12 |
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| including ([A-Za-z ]+) ([0-9,]+) | <d>$1</d> <n>$2</n> | 32 |
| inclusding-半角スペース-丸括弧-角括弧-A-ハイフン-Za-ハイフン-z-半角スペース-角括弧-プラス-丸括弧-半角スペース-丸括弧-角括弧-0-ハイフン-9-カンマ-角括弧-プラス-丸括弧 | 小なり-ディー-大なり-ドル-1-小なり-スラッシュ-ディー-大なり-半角スペース-小なり-エヌ-大なり-ドル-1-小なり-スラッシュ-エヌ-大なり | |
| including-疾患名を1番目の参照-半角スペース-死亡者数を2番目の参照 | 疾患名を<d>で囲み内容はマッチパターン1を参照-死亡者数を<n>で囲み内容はマッチパターン2を参照 |
7-8-2. including 罹患者・死亡者数→疾患名
| 置換前 | including 4 from tuberculosis. |
| 置換後 | <d>tuberculosis</d> <n>4</n> |
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| including ([0-9]+) from ([A-Za-z ]+)[.,] | <d>$2</d> <n>$1</n> | 12 |
| including-半角スペース-丸括弧-角括弧-丸括弧-角括弧-0-ハイフン-9-カンマ-角括弧-プラス-丸括弧-半角スペース-from-半角スペース-A-ハイフン-Za-ハイフン-z-半角スペース-角括弧-プラス-丸括弧-角括弧-ピリオド-カンマ-角括弧 | 小なり-ディー-大なり-ドル-2-小なり-スラッシュ-ディー-大なり-半角スペース-小なり-エヌ-大なり-ドル-2-小なり-スラッシュ-エヌ-大なり | |
| including-死亡者数を1番目の参照-半角スペース-from-半角スペース-疾患名を2番目の参照-ピリオド/カンマのどちらか | 疾患名を<d>で囲み内容はマッチパターン2を参照-死亡者数を<n>で囲み内容はマッチパターン1を参照 |
次に、既存のマーカー(なんらかの終了タグ)の後に表示される疾患-カウントのペアに繰り返し一致させます。
“>”以降にアルファベットが続いて…と処理したいところですが、その順番だと”and”が入るパターンでズレてしまいます。ですから先にandのパターンを処理することにしましょう。
この処理をする前に「大文字と小文字を区別する」のオプション(「Aa」)がオンになっているか確認してください。
7-8-3. and 罹患者・死亡者数 from 疾患名
| 置換前 | plague 1 and 13 from tuberculosis |
| 置換後 | plague 1 tuberculosis 13 |
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| and ([0-9,]+) from ([A-Za-z ]+) | $2 $1 | 34 |
| and-半角スペース-丸括弧-0-ハイフン-9-カンマ-角括弧-プラス-丸括弧-半角スペース-from-半角スペース-丸括弧-角括弧-A-ハイフン-Za-ハイフン-z-半角スペース-角括弧-プラス-丸括弧 | ドル-2-半角スペース-ドル-1 | |
| and-死亡者数を1番目の参照-半角スペース-from-疾患名を2番目の参照 | 疾患名-半角スペース-死亡者数 |
7-8-3. and 疾患名→罹患者・死亡者数
| 置換前 | fever 6 and smallpox 24 |
| 置換後 | fever 6 smallpox 24 |
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| and[ ]([A-Za-z ]+\d+) | $1 | 48 |
| and-角括弧-半角スペース-角括弧-A-ハイフン-Za-ハイフン-z-半角スペース-角括弧-プラス- バックスラッシュ-d-プラス-丸括弧 | ドル-1 |
これらの処理のあとで、前から順番に疾患名→罹患者・死亡者数のタグ付けの処理をしていきます。
7-8-4. 疾患名→罹患者・死亡者数の連続処理
いま、疾患名と罹患者・死亡者数は半角スペースで並んでいます。これを連続処理でどんどんタグ付けしていきましょう。
| 置換前 | </n> enteric fever 12 scarlet fever 2 |
| 置換後 | </n> <d>enteric fever</d> <n>12</n> |
罹患者・死亡者数の直前に置かれる終了タグには、</n>と</c>、そして</N>があります。
</N>の後は疾患名→罹患者・死亡者という書き方になっていないので、</n>と</c>に限定して疾患名と罹患者・死亡者数をマークアップします。
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| ([nc]>) ([A-Za-z ]+) ([0-9,]+)[.]? | $1 <d>$2</d> <n>$3</n> | 81 |
| 丸括弧-角括弧-nc-角括弧-大なり-丸括弧-半角スペース-丸括弧-角括弧-A-ハイフン-Za-ハイフン-z-半角スペース-角括弧-プラス-丸括弧-半角スペース-丸括弧-角括弧-0-ハイフン-9-カンマ-角括弧-プラス-丸括弧-角括弧-ピリオド-角括弧-クエスチョン | ドル-1-半角スペース-小なり-ディー-大なり-ドル-2-小なり-スラッシュ-ディー-大なり-半角スペース-小なり-エヌ-大なり-ドル-3-小なり-スラッシュ-エヌ-大なり |
この置き換えを、これ以上の一致がなくなるまで必要な回数繰り返します(2回目:74件、3回目:64件、4回目:37件、5回目:22件、6回目:12件、7回目:4件)。
7-8-5. 罹患者・死亡者数→疾患名
まだ死亡者数→疾患名のパターンが残っているので処理していきます。このパターンでは、death from, deaths from, fromの3種類が使われています。応用が入るので少し難しいですが、以下のように一括で処理してしまいましょう。
以下のパターンを検索欄に入力します。
([0-9,]+) (death |deaths )?from ([A-Za-z ]+)[,.]?
選択結果をよく見てみましょう。
- 1 death from enteric fever tuberculosis reported(17行目)
- 1 death from diphtheria enteric fever(21行目)
この2箇所には、2つの疾患名の間にカンマが入っていないがためにマッチして欲しくない文字列がマッチしています(赤字部分)。
ここは手動で間にカンマを入れてしまうのが楽なのですが、ついでに17行目のreportedが邪魔なので消してしまいましょう。
| 置換前 | 置換後 |
|---|---|
| 1 death from enteric fever tuberculosis reported | 1 death from enteric fever, tuberculosis |
| 1 death from diphtheria enteric fever | 1 death from diphtheria, enteric fever |
これで望ましいパターンだけがマッチしました。
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| ([0-9,]+) (death |deaths )?from ([A-Za-z ]+)[,.]? | <d>$3</d> <n>$1</n> | 9 |
| 丸括弧-角括弧-0-ハイフン-9-カンマ-角括弧-プラス-丸括弧-半角スペース-丸括弧-death-半角スペース-パイプ-deaths-半角スペース-丸括弧-クエスチョン-from-半角スペース-丸括弧-角括弧-A-ハイフン-Za-ハイフン-z-半角スペース-角括弧-プラス-丸括弧-角括弧-カンマ-ピリオド-角括弧-クエスチョン | 小なり-ディー-大なり-ドル-2-小なり-スラッシュ-ディー-大なり-半角スペース-小なり-エヌ-大なり-ドル-3-小なり-スラッシュ-エヌ-大なり | |
| 数字の組み合わせ-deathかdeathsのどちらかが入るかもしれない-半角スペース-from-半角スペース-アルファベットと半角の組み合わせ-カンマかピリオドが入るかもしれない |
7-8-6. Morbidity以下の処理
次に、Morbidity以下のパターンを置き換えていきます。
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| ([A-Za-z][a-z ]+), ([0-9]+) cases.+?counties[ ;.] | <d>$1</d> <n>$2</n> | 3 |
| 丸括弧-角括弧-A-ハイフン-Za-ハイフン-z-角括弧-角括弧-a-ハイフン-z-半角スペース-角括弧-プラス-丸括弧-カンマ-半角スペース-丸括弧-角括弧-0-ハイフン-9-角括弧-プラス-丸括弧-半角スペース-cases-ピリオド-プラス-クエスション-counties-角括弧-半角スペース-セミコロン-ピリオド-角括弧 | 小なり-ディー-大なり-ドル-2-小なり-スラッシュ-ディー-大なり-半角スペース-小なり-エヌ-大なり-ドル-3-小なり-スラッシュ-エヌ-大なり | |
| アルファベットの組み合わせ(頭文字は大文字の可能性あり)-カンマ-半かスペース-数字の組み合わせ-半角スペース-cases-1文字以上の繰り返し-counties-半角スペースかセミコロンかピリオドのいずれか |
7-9. 州名と都市名のセルを整える
ここで、Excelにコピー&ペースト(「貼り付け先の書式に合わせる」)またはExcelでtsvファイルをインポートして、どれだけゴールに近づいているかを確認しましょう。位置データをセルに正常に分離していますが、それらのセルはまだ縦に整列していません(=バラバラの列に配置されています)。すべての時間の参照をC列に入れたいです。
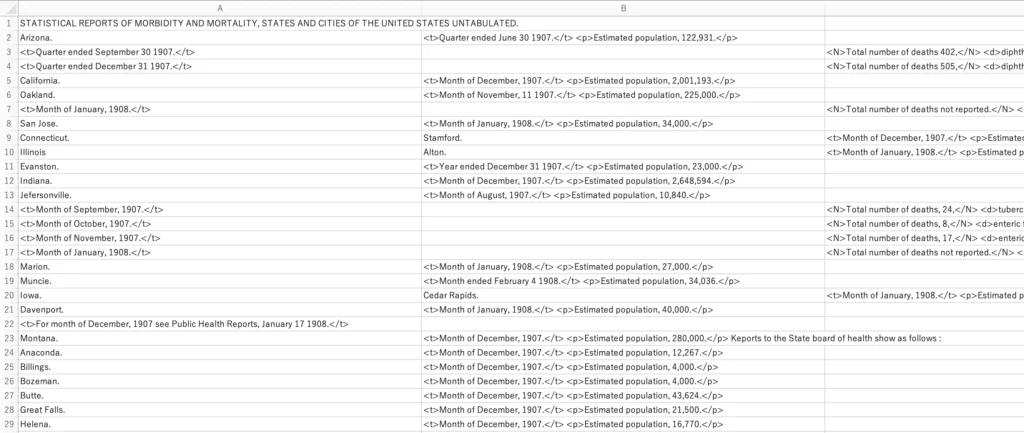
2つの位置情報の列を持つインスタンスは、すでにタブ分けされていて問題ないはずです。1つの位置情報しかない行と位置情報が存在しない行には、追加の列が必要です。ほとんどが都市なので、都市名をB列に入れ、州の名前でB列に入ってしまっているものを手動でA列に戻す必要があります。
VSCodeのウィンドウに戻り、州名をA列、都市名をB列に入れるため、時間に関する言及であるタグを目印に、タブで列を調整しましょう。
7-9-1. 州名がなく、都市名だけがある場合
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| ^([A-Za-z .]+\t<t>) | \t$1 | 30 |
| キャレット-丸括弧-角括弧-A-ハイフン-Za-ハイフン-z-半角スペース-ピリオド-角括弧-プラス-バックスラッシュ-ティー-小なり-ティー-大なり-丸括弧 | バックスラッシュ-ティー-ドル-1 | |
| 行頭-アルファベット/半角スペース-ピリオドの1回以上の繰り返し-タブ-<t>タグを1番目に参照 | タブ-1番目のパターンを参照 |
7-9-2. 州名も都市名もない場合
次は、上の行と同じ場所の情報が続いているものの、期間が異なる場合です。この場合は州名も都市名もないパターンとして考え、タブだけを挿入します。
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| ^<t> | \t\t<t> | 20 |
| キャレット-小なり-ティー-大なり | バックスラッシュ-ティー-バックスラッシュ-ティー-小なり-ティー-大なり |
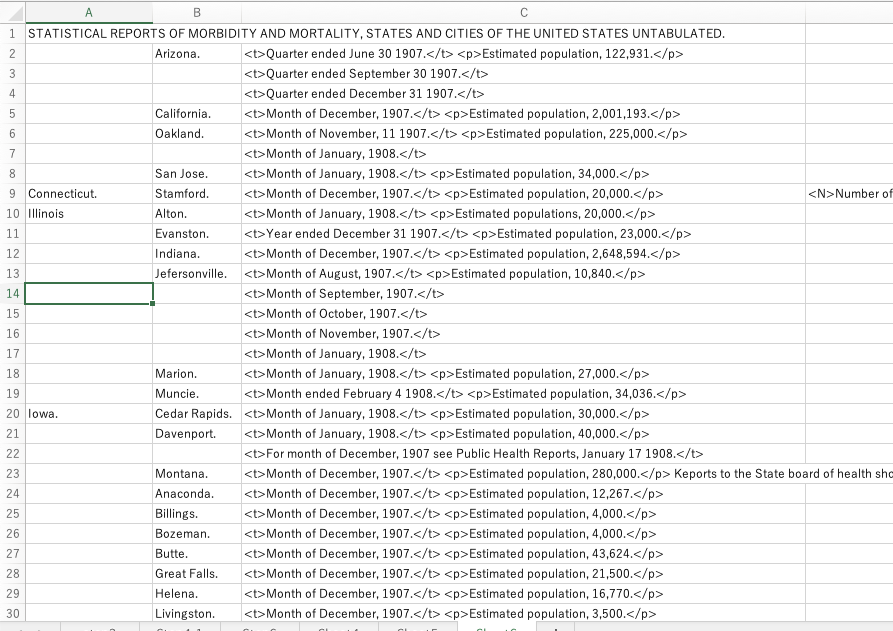
この内容を再度Excelに貼り付けると、最初の数列は見やすくなるはずです。州の名前を修正したい場合は、州の名前の前のタブ文字を削除し、新しいタブ文字を導入してVSCodeで修正することができます。あるいは、VSCodeでの作業が完了するのを待ち、それを後にExcelで修正することもできます。しかし、すべての作業はまだ完了していません。
7-10. 疾患名と罹患者数を縦に並べる
疾患名のリストの取り扱い方法を決定する必要があります。行ごとに異なるリストがあり、長さも異なります。州名や都市名と同様に、タブ文字を挿入して、各病名や死亡数または罹患者数を別の列に入れるのは簡単ですが、それらの列はそれほど役に立たないでしょう。病名と集計は縦に整列しません。代わりに、各病名ごとに新しい行を作ることができます。報告書では死亡数と罹患者数を区別しており、これらはすでに”Cases:”または”Morbidity”で便利に分けられ、<c>タグでマークアップされています。
“Cases:”または”Morbidity”のリストのための新しい行を作り始めます。それらを個別に取り扱うことができます。
VSCodeに戻ってください。
7-10-1. 死亡データと疾患データを行で分け、地名・期間とともに表示させる
まずは、死亡に関するデータと疾患に関するデータの両方が入っている都市名の行を、死亡データと疾患データの2行に分ける処理をしましょう。
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| ^(.*\t)(.*\t)(<t>.*</t>)(.*)(<c>.*)$ | $1$2$3$4\n$1$2$3\t$5 | 50 |
| キャレット-丸括弧-ピリオド-アスタリスク-バックスラッシュ-ティー-丸括弧-丸括弧-ピリオド-アスタリスク-バックスラッシュ-ティー-丸括弧-丸括弧-小なり-ティー-大なりピリオド-アスタリスク-小なり-スラッシュ-ティー-大なり-丸括弧-丸括弧-ピリオド-アスタリスク-丸括弧-丸括弧-小なり-シー-大なり-ピリオド-アスタリスク-ドル-丸括弧 | ドル-1-ドル-2-ドル-3-ドル-4-バックスラッシュ-エヌ-ドル-1-ドル-2-ドル-3-バックスラッシュ-ティー-ドル-5 | |
| 行頭-タブまでを参照1-タブまでを参照2-<t>タブで囲まれた部分を参照3-</t>と<c>の間を参照4-<c>から行末までを参照5 | 1番目(州名)を参照-2番目(都市名)を参照-3番目(集計期間)を参照-4番目(疾患以外のデータ)を参照-改行-1番目(州名)を参照-2番目(都市名)を参照-3番目(集計期間)を参照-タブ-5番目(疾患データ)を参照 |
ここで気づくべきことは、一部の置換パターン($1$2$3)を2回使用していることです。時間の参照までの3つのフィールドに一致し、4番目のグループで<c>の前のすべてに一致し、5番目のグループで<c>からすべてに一致します。置換パターンでは、グループ1-4を順序通りに戻し、新しい行を導入して、グループ1-3を再度表示し、その後にタブとグループ5を表示します。事実上、疾患データを新しい行に移動し、場所と時間のフィールドをそのままコピー&ペーストしました。
7-10-2. 疾患名と罹患者数を1項目ごとに改行する
さらに進んで、疾患名と罹患者数のリストをすべて別々の行に分割しましょう。
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| ^(.*\t)(.*\t)(<t>.*</t>\t)(<c>)(.*)(:</c>.*)<d>(.*)</d>.*<n>(.*)</n>(.*)$ | $1$2$3$5\t$7\t$8\n$1$2$3$4$5$6$9 | 50 |
| キャレット-丸括弧-ピリオド-アスタリスク-バックスラッシュ-ティー-丸括弧-丸括弧-ピリオド-アスタリスク-バックスラッシュ-ティー-丸括弧-丸括弧-小なり-ティー-大なり-ピリオド-アスタリスク-小なり-ティー-スラッシュ-ティー-大なり-バックスラッシュ-ティー-丸括弧-丸括弧-小なり-シー-大なり-丸括弧-丸括弧-ピリオド-アスタリスク-丸括弧-丸括弧-コロン-小なり-スラッシュ-シー-大なり-ピリオド-アスタリスク-丸括弧-小なり-ディー-大なり-丸括弧-ピリオド-アスタリスク-丸括弧-小なり-スラッシュ-ディー-大なり-ピリオド-アスタリスク-小なり-エヌ-大なり-丸括弧-ピリオド-アスタリスク-丸括弧-小なり-スラッシュ-エヌ-大なり-丸括弧-ピリオド-アスタリスク-丸括弧-ドル | ドル-1-ドル-2-ドル-3-ドル-5-バックスラッシュ-ティー-ドル-7-バックスラッシュ-ティー-ドル-8-バックスラッシュ-エヌ-ドル-1-ドル-2-ドル-3-ドル-4-ドル-5-ドル-6-ドル-9 | |
| 行頭-タブまでを参照1-タブまでを参照2-<t>からタブまでを参照3-<c>を参照4-<c>と:</c>に囲まれたCasesまたはMorbidity(半角スペースを含む場合もある)を参照5-:</c>から<d>までを参照6-<d>-<d>タグの中身を参照7-</d>-0文字以上の文字列-<n>-<n>タグの中身を参照8-</n>-0文字以上の文字列を参照9(ここにはまだ行分けされていない要素がすべて入る)-行末 | 1番目を参照-2番目を参照-3番目を参照-5番目を参照-タブ-7番目を参照-タブ-8番目を参照-改行-1番目を参照-2番目を参照-3番目を参照-5番目を参照-6番目を参照-9番目を参照 |
これを一致しなくなるまで必要な回数繰り返します(2回目47件、3回目44件、4回目27件、5回目17件、6回目10件、7回目3件)。
7-10-3. 疾患名と罹患者数の入っていない行を削除する
最後に、残った<c>Cases:</c>または<c>Morbidity:</c>だけの行を消します。すでに消したい行以外には<c>タグは残っていないはずなので、マッチパターンにはシンプルなものを適用できます。
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| ^.+<c>.*\n | 50 | |
| キャレット-ピリオド-プラス-小なり-シー-大なり-ピリオド-アスタリスク-バックスラッシュ-エヌ | (何も入力しない) | |
| 文頭-1文字以上の文字列-<c>タグ-0文字以上の文字列-改行 |
7-10-4. 疾患名と死亡者数を1項目ごとに改行する
同様に、すべての死亡リストを別々の行に分割します。
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| ^(.*</t>)(.*\t)(.*?)<d>(.*?)</d>.*?<n>(.*?)</n>(.*)$ | $1$2$3\n$1\tDeaths\t$4\t$5\n$1\tDeaths\t$6 | 48 |
| キャレット-丸括弧-ピリオド-アスタリスク-小なり-スラッシュ-ティー-大なり-丸括弧-丸括弧-ピリオド-アスタリスク-バックスラッシュ-ティー-丸括弧-丸括弧-ピリオド-アスタリスク-クエスチョン-小なり-ディー-大なり-丸括弧-ピリオド-アスタリスク-クエスチョン-丸括弧-小なり-スラッシュ-ディー-大なり-ピリオド-アスタリスク-クエスチョン-小なり-エヌ-大なり-丸括弧-ピリオド-アスタリスク-クエスチョン-丸括弧-小なり-スラッシュ-エヌ-大なり-丸括弧-ピリオド-アスタリスク-丸括弧-ドル | ドル-1-ドル-2-ドル-3-バックスラッシュ-エヌ-ドル-1-バックスラッシュ-ティー-Deaths-バックスラッシュ-ティー-ドル-4-ドル-5-バックスラッシュ-エヌ-ドル-1-バックスラッシュ-ティー-Deaths-バックスラッシュ-ティー-ドル-6 | |
| 文頭-</t>までの文字列を1番目の参照-タブまでの文字列を2番目の参照-タブから<d>までの文字列を3番目の参照-<d>-<d>タグで囲まれた文字列を4番目の参照-</d>-0文字以上の文字列(多くは半角スペースが入っている)-<n>-<n>タグで囲まれた数字を5番目の参照-</n>-0文字以上の文字列を6番目の参照-行末 | 1番目を参照-2番目を参照-3番目を参照-改行-1番目を参照-タブ-Deaths-タブ-4番目を参照-タブ-5番目を参照-改行-1番目を参照-タブ-Deaths-タブ-6番目を参照 |
2回目以降は書き方のパターンが変わる(<p>や<N>などが入らない)ので、以下のように処理します。
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| ^(.*Deaths\t).*?<d>(.*?)</d>.*?<n>(.*?)</n>(.*)$ | $1$2\t$3\n$1$4 | 34 |
| キャレット-丸括弧-ピリオド-アスタリスク-Deaths-バックスラッシュ-ティー-丸括弧-ピリオド-アスタリスク-クエスチョン-小なり-ディー-大なり-丸括弧-ピリオド-アスタリスク-クエスチョン-丸括弧-小なり-スラッシュ-ディー-大なり-ピリオド-アスタリスク-クエスチョン-小なり-エヌ-大なり-丸括弧-ピリオド-アスタリスク-クエスチョン-丸括弧-小なり-スラッシュ-エヌ-大なり-丸括弧-ピリオド-アスタリスク-丸括弧-ドル | ドル-1-ドル-2-バックスラッシュ-ティー-ドル-3-バックスラッシュ-エヌ-ドル-1-ドル-4 | |
| 行頭-Deathsの後のタブまでを1番目の参照-最初の<d>までの0文字以上の文字列-<d>-<d>タグで囲まれた文字列を2番目の参照-</d>-最初の<n>までの0文字以上の文字列-<n>-<n>タグで囲まれた文字列を3番目の参照 -</n>-行末までの0文字以上の文字列-行末 | 1番目を参照-2番目を参照-タブ-3番目を参照-改行-1番目を参照-4番目を参照 |
これを一致しなくなるまで必要な回数繰り返します(2回目29件、3回目22件、4回目11件、5回目5件、6回目2件、7回目1件)。
7-10-5. 疾患名と死亡者数の入っていない行を削除する
最後に、残ったDeathsだけの行を消します。まず、以下のパターンを検索欄に入力してマッチした文字列を見てみましょう。
^.*Deaths\t[ ]
このパターンでは48件マッチしますが、60行目にはDeathsの後に”tuberculosis 11.“という文字列(例外)が残ってしまっています。よく見ると似たパターン(<d>と<n>をつけ忘れていた)が4件存在します。以下の文字列を検索してみると未処理のパターンが明らかになります。
Deaths\t.*([a-z]+) ([0-9]+)\.
これらを処理しないままに消してはならないので、先に修正します。
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| Deaths\t[ ]([a-z ]+) ([0-9]+)\. | Deaths\t$1\t$2 | 4 |
| Deaths-バックスラッシュ-ティー-角括弧-半角スペース-角括弧-丸括弧-角括弧-a-ハイフン-z-半角スペース-角括弧-プラス-丸括弧-半角スペース-丸括弧-角括弧-0-ハイフン-9-角括弧-プラス-丸括弧-バックスラッシュ-ピリオド | Deaths-バックスラッシュ-ティー-ドル-1-バックスラッシュ-ティー-ドル-2 | |
| Deaths-タブ-半角スペース-小文字アルファベット/半角スペースのいずれかの1回以上の繰り返しを1番目の参照-半角スペース-数字1回以上の繰り返しを2番目の参照 | Deaths-タブ-1番目の参照-タブ-2番目の参照 |
例外を処理できたので、今度こそ残ったDeathsだけの行を消します。
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| ^.*Deaths\t[ ]\n | 44 | |
| キャレット-ピリオド-アスタリスク-Deaths-バックスラッシュ-ティー-角括弧-半角スペース-角括弧-バックスラッシュ-エヌ | (何も入力しない) | |
| 行頭-Deathsまでの文字列-タブ-半角スペース-改行 |
この段階で、タブ形式の理想の構造に非常に近づいているのがわかります。
7-11. 残っているタグを削除する
最後に、便宜につけておいたタグのうち残っているタグを削除します。
| マッチパターン | 置換文字列 | 一致パターン |
|---|---|---|
| <[tpN]>(.*?)</[tpN]> | $1 | 500 |
| 小なり-角括弧-tpN-角括弧-大なり-丸括弧-ピリオド-アスタリスク-クエスチョン-丸括弧-小なり-スラッシュ-角括弧-tpN-角括弧-大なり | ドル-1 | |
| <t>か<p>か<N>のいずれか-タグに囲まれた文字列(一番近い<まで)を1番目の参照-</t>か</p>か</N>のいずれか | 1番目の参照 |
これをExcelにコピーして貼り付けると、(ほぼ)整然としたテーブルが表示されるはずです。
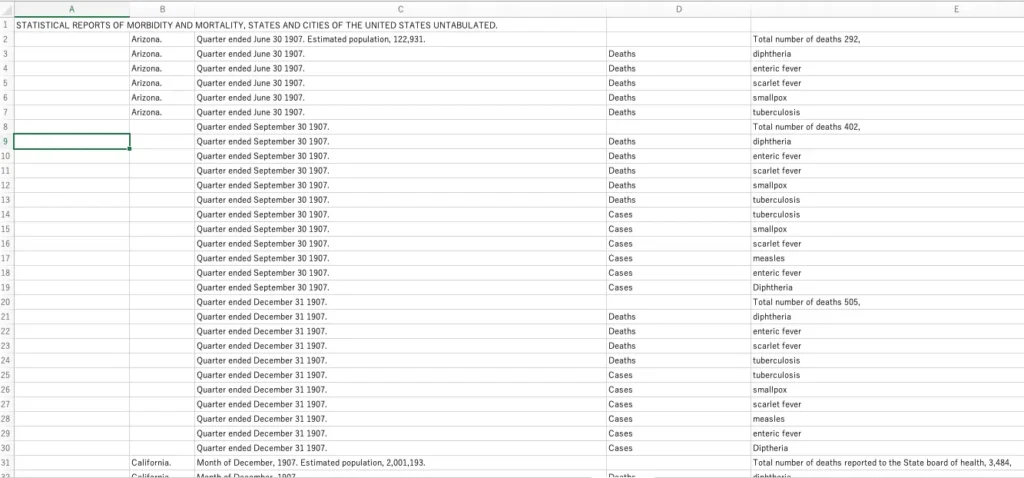
これが練習ではなく、研究や出版のためのソースを編集している場合、まだ修正する必要がある点があります。推定人口の数字は何もしていません。私たちのパターンマッチングは、すべてを管理するのに十分洗練されていませんでした。「総死亡数292、含む」というようなパターンがない行では、「」のマーカーをすでに入れていたと仮定して後続のパターンすべてが見逃されました。
次の可能性
これらの問題の一部は、追加のパターンマッチング手順で修正できるかもしれません。一部は途中の特定のポイントでのソースドキュメントの手動編集によって、また一部はスプレッドシートや同様の表形式での後からのデータ編集によって修正できるでしょう。
また、テーブルの他の構造も検討したいかもしれません。たとえば、死亡者数と罹患者数を異なる列に分けた方が、集計するのが便利かもしれません。ワードプロセッサは、これらの種類の構造を利用するための最良のツールではありません。スプレッドシート、XML、データを扱うためのプログラムツールの方が役立ちそうです。しかし、ワードプロセッサには高度な検索・置換機能があり、これを知ることは良いことです。正規表現や高度なパターンマッチングは編集に役立ち、私たちが一致させたい、または作成したい暗黙の構造とより明示的な構造との間の橋渡しをすることができます。
Internet Archiveからは、この報告書のような公衆衛生に関する報告書が400以上利用可能です。これらすべてを表形式で整理したい場合、Excelは最良の主要ツールではありません。Python、Ruby、またはシェルスクリプトを少し学ぶ方が良いでしょう。プログラマー向けのプレーンテキストエディタ、EmacsやVi、Vimのようなクラシックなものを含むものは、正規表現のサポートやプログラム的な方法でプレーンテキストを扱うための他の便利な機能を備えています。Unixのようなシェルコマンドラインを開くことに抵抗がない場合(MacやLinux、または仮想マシンやCygwin環境を通じてのWindows)、”grep”のようなツールで検索したり、”sed”で行指向の置換を行うために正規表現を非常にうまく学び使用することができます。
正規表現は、一度に数百のファイルのパターンを扱う際に非常に役立ちます。この例で使用したパターンは、長いテキストや大量のテキストセットに適用した際に間違いであると確実に思われる仮定を取り扱うために、洗練され拡張される必要がありますが、プログラム言語を使えば、私たちがやっていることを短いスクリプトに記録し、繰り返し洗練し再実行することで、目指す結果に近づけることができます。
もっと学ぶために
Wikipediaの正規表現に関するページは、正規表現の簡潔な歴史や形式言語理論との関連、さらには文法の変種や公式の標準化の取り組みの概要を知るのに役立つ場所です。
実際の使用のためには、使用するツールのドキュメントが非常に価値があります。特に、正規表現の実装が特に独特である可能性が高いワードプロセッシングの環境での作業には特にそうです。プログラミングの文脈で正規表現をどのように使用するかを学ぶための多くのリソースがあります。最も適したものは、最初に始めるのに最も馴染みがある、または便利なプログラミング言語によって異なるかもしれません。
無料で利用できるウェブベースの正規表現エディターがいくつかあります。Rubyプログラミング言語を基盤としたRubularは、サンプルテキストに対して正規表現をテストし、マッチとマッチしたグループを動的に表示する役立つインターフェースを持っています。ピッツバーグ大学のスラブ言語および文学科の学科長であるDavid Birnbaumは、正規表現やXMLツールを使用して、TEI/XMLでプレーンテキストファイルにマークアップをする方法に関する良い資料を持っています。
コメント